Lost in the Literature: AI and the Problem of Mathematical Search
In 2016, Terry Tao published a whimsical blog post in which he derived a mathematical formula for grading. Rather than relying on binary “True/False” answers, he proposed a scheme in which students would report both an answer and a subjective confidence level. Using ideas from information theory, Tao arrived at a logarithmic scoring rule designed to incentivize students to report their true beliefs rather than strategically hedging.
Almost immediately, a commenter going by sflicht pointed out that Tao had independently rediscovered a well-known concept: proper scoring rules, a class of mechanisms long studied in statistics and decision theory for exactly this purpose.

Tao explicitly noted in the original post that he suspected the construction was not new, but that he had been unable to locate an existing reference. A decade later, one might speculate that such a blog post might never have been written at all, having been replaced by a single query to ChatGPT… or perhaps not. Despite the remarkable advances in large language models, we still lack anything resembling a comprehensive semantic search engine for the mathematical literature.
The old dream of mathematicians is not to sift through piles of papers, but to retrieve from the literature the exact statement that answers their question under the right hypotheses.
If agentic systems help navigate the literature, they remain bottlenecked by the structure of the data itself: mathematics is stored as PDFs meant for humans, not as a database of addressable statements.
We outline the problem, and present a first brick toward building searchable mathematical data.
As discussed at length in earlier posts, much of the AI research effort in mathematics has instead been directed toward theorem-proving systems and high-visibility benchmarks, such as claims of International Mathematical Olympiad–level performance, rather than toward tools that helps surface existing mathematical knowledge.
The various modes of scientific literature search
Leaving the comparatively clean domain of theorem proving, we enter the more diffuse problem of navigating the scientific literature. “Search” in this context is not a single task but a family of distinct retrieval and synthesis problems, each with different technical requirements and failure modes.
1.Field discovery and orientation.
When encountering an unfamiliar area, the goal is to obtain a high-level map of the field: core questions, canonical references, recent trends, and vocabulary. This use case is now reasonably well addressed by so-called Deep Research modes in large language models, as well as by dedicated research-assistant tools such as Elicit, SciSpace, or Jenni AI.
These systems typically implement multi-stage pipelines: query expansion, large-scale paper retrieval, clustering, and summarization. The main challenges here are engineering rather than conceptual—scaling to hundreds or thousands of papers while maintaining topical relevance and avoiding hallucinated structure.
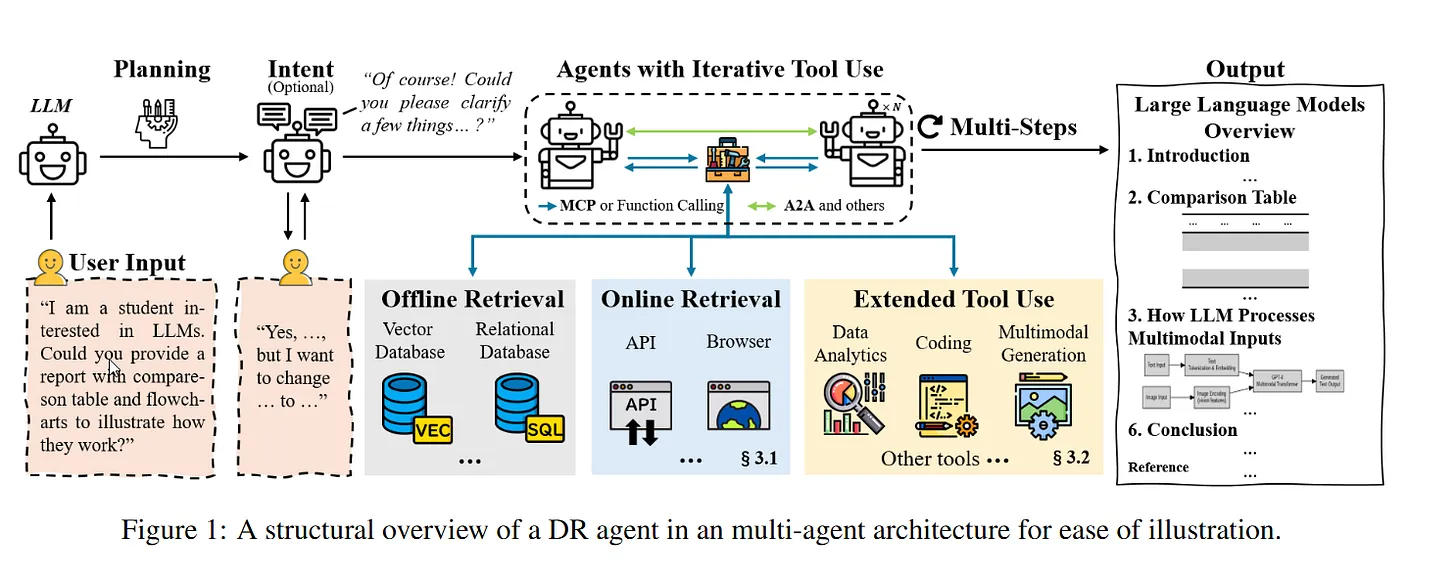
2.Paper-level understanding.
A second, narrower task is the comprehension of a specific paper. This is addressed by the same tools via “chat with this paper” interfaces (e.g. AlphaXiv). In many cases, the full text fits within the model’s context window, reducing the problem to careful conditioned generation. The central difficulty is no longer retrieval but calibration: the model must remain faithful to the source while providing clarifying explanations, filling in omitted steps, and translating between notational conventions.
3.Statement-level retrieval.
A qualitatively different task is the direct retrieval of a specific statement that answers a concrete query. In chemistry or pharmacology, this might involve identifying the precise formula of a compound or a known reaction pathway. In mathematics, it could correspond to locating a less widely known convexity inequality or a sharp bound buried in a specialized paper.
This is precisely one of the main motivation for Stella, an initiative to collect technical lemmas at the research frontier to better test LLMs’ capabilities.

This mode of search requires fine-grained semantic indexing at the level of definitions, lemmas, theorems and propositions.
4.Framework-level identification or conceptual attribution
A fourth mode of search, still poorly addressed by existing systems, is the identification of the conceptual framework to which a given construction belongs. In this case, the input is neither a keyword query nor a reference to an existing result, but a problem formulation, a methodological description, or an ad hoc construction expressed in the user’s own terms. The desired output is a name: the established theory, framework, or class of objects in which this idea has already been formalized and studied.

Tao’s grading scheme provides a canonical example. The difficulty was not in deriving the logarithmic scoring rule, nor in understanding an existing paper, but in recognizing that the construction instantiated a known concept.
This task sits between statement-level retrieval and field discovery, and it is particularly acute in mathematics or physics, where equivalent ideas routinely appear under different guises, notations, or motivations. Bridging this gap requires more than better document retrieval: it requires systems capable of mapping informal or novel formulations to existing conceptual structures.
This level of conceptual mapping is even more challenging than statement-level retrieval. Before a system can recognize the underlying framework of a construction, it must first be able to retrieve the relevant statements or results with precision. Without that foundation, true attribution remains out of reach.
Achieving this requires tools designed specifically for mathematical search, rather than relying on general-purpose engines or broad literature surveys.
Mathematical Information Retrieval: An Old Dream Revisited
“Les mathématiciens se contentent de mettre leur production à la disposition de tous, comme sur des étagères où l’on peut venir se servir.”1 Jean-Pierre Serre, according to Michel Broué
Unlike broad literature survey tasks, retrieving precise mathematical statements from a corpus presents unique challenges. It cannot rely solely on large language models, either for generating effective queries for general-purpose search engines or for leveraging their internal knowledge. Instead, it calls for specialized search engines built over curated mathematical corpora. The goal is to return the relevant statements faithfully, without hallucination or ambiguous reformulation. In short, precision is prioritized over fluency.
The idea of a fully searchable mathematical corpus is far from new. In the early 1990s, following the rise of the Internet, mathematicians envisioned the digitalization, indexing, and retrieval of all mathematical knowledge—a vision formalized in the field of Mathematical Knowledge Management. Ambitious initiatives such as the QED Manifesto and PlanetMath were amongst the first that attempted to realize this dream, though at the time it remained largely out of reach2.
 The QED Manifesto
The QED Manifesto
The 2010 survey Digital Mathematics Libraries: The Good, the Bad, the Ugly made explicit the gap between digitization and genuine semantic access to mathematical content, a diagnosis refined by the committee on Planning a Global Library of the Mathematical Sciences, which called for a sustained global infrastructure beyond document repositories. Initiatives such as the European Digital Mathematic library and later the International Mathematical Knowledge Trust sought to act on this vision but many have since slowed or become largely inactive, highlighting how difficult it has been to build a durable semantic search infrastructure for mathematics.
Advances in search and indexing technologies, combined with the rise of generative AI, gives us a new hope for building fine-grained, concept-aware access to mathematical knowledge.
Yet mathematics poses inherent difficulties that distinguish it from natural-language text:
Technical language is highly sensitive to small perturbations (say a change of sign), while simultaneously exhibiting invariance under notation changes—formally known as α-equivalence.
Standard LLMs were not trained to handle these subtleties, but they perform surprisingly well on conventional mathematics, even at the graduate level. When queries concern research-level results that appear only rarely in the literature, however, their performance degrades sharply, highlighting the need for specialized retrieval systems3.
Another promising avenue leverages formalized mathematics. Formal proof assistants like Lean and Coq provide structured, machine-readable representations of mathematical knowledge, making them ideal substrates for building search engines that go beyond keyword or embedding-based retrieval.
Specialized Search Engines over Formalized Mathematics
Indeed, with the recent push toward formalized languages to support AI-assisted theorem proving, a number of search engines have emerged on top of these frameworks—examples include Loogle, LeanSearch, LeanFinder, and Leandex… just for Lean.
 Lean Finder
Lean Finder
These engines benefit from two key advantages:
- (1) the inherent structure of code and explicit dependencies between definitions, theorems, and proofs, and
- (2) the fact that large language models have been extensively trained on code, giving them a built-in understanding of programming-like languages.
However, formalized mathematics still represents only a tiny fraction of the total body of mathematical knowledge. Scaling to a full semantic search engine for all mathematics remains daunting. Challenges include the sheer volume and heterogeneity of mathematical data—from scanned books to LaTeX documents—requiring extraction of statements and proofs, and the fact that moving beyond formal languages sacrifices the logical guarantees that make formalized corpora so precise.
Restricting the Problem: Focusing on Accessible Papers
When a problem is too hard in full generality, mathematicians often simplify it. Here, we begin by focusing on papers available as LaTeX on arXiv. Handling the rest of the literature—scanned books, PDFs, or other formats—is largely an engineering challenge (data access, OCR, and formatting), not a conceptual one.
We now describe how we can build a searchable mathematical statements dataset from arXiv. All the underlying code is available in the arxitex repository.
The first goal is to extract all mathematical artifacts from each paper: definitions, lemmas, propositions, theorems, and corollaries along with their proofs. This can be done with carefully crafted regex heuristics that handle custom macros like \newtheorem. Citations are then linked back to other arXiv papers, forming a navigable web of references.
Making artifacts self‑contained
Extracting theorems and definitions is not enough as a statement almost never carries its full meaning on its own. Papers are (usually) written linearly, so authors freely use symbols and jargon that were introduced earlier, sometimes in a Definition environment, but often in a single sentence like “Let (f) be …”…
For a semantic search engine, this is a problem. If you land on an isolated lemma, you shouldn’t need to scroll 20 pages backward just to learn what that (\varphi), (\mathcal F), or “union‑closed” means.
This is why we need to proceed to an artifact enhancement step. The idea is simple:
-
Collect definitions into a paper‑local “definition bank”.
- First, we harvest all explicit definitions from the paper (Definition environments).
- Then, when the paper introduces a symbol informally, we optionally ask an LLM to write a short definition from nearby context (best‑effort, and clearly treated as derived context rather than a formal guarantee).
-
For every artifact, prepend the definitions it depends on. We scan the artifact for its key terms and symbols, look them up in the definition bank, and attach them as a small “Prerequisite Definitions” block above the statement.
The result is that each extracted theorem/lemma/corollary becomes closer to a standalone object you can read in isolation, index for search, and later display as a node in a dependency graph without losing essential context4.
Example: enhancing a theorem artifact
To see what this looks like in practice, consider Theorem 1.3 from Approximate Union Closed Set Systems. The original theorem reads as follows:

This relies on several pieces of context that appear earlier or are assumed to be standard: what a set system or is, what
(1−ϵ)-approximate union closed means. After artifact enhancement, the same theorem would be stored and presented as:
Set system. A set system \( F \) is a collection of subsets of a finite universe \( U \); that is, $$ F \subseteq \mathcal P(U). $$
Union of sets. For sets \( A, B \subseteq U \), their union \( A \cup B \) consists of all elements belonging to \( A \) or \( B \).
\((1-\varepsilon)\)-approximate union closed. A set system \( F \) is \((1-\varepsilon)\)-approximate union closed if at least a \((1-\varepsilon)\)-fraction of all ordered pairs $$ (A,B) \in F \times F $$ satisfy $$ A \cup B \in F. $$
Enhanced Theorem 1.3
Let \( F \) be a \((1-\varepsilon)\)-approximate union closed set system on a finite universe \( U \), with \( \varepsilon < \tfrac12 \). Then there exists an element \( x \in U \) that is contained in at least a \( \psi - \delta \) fraction of the sets in \( F \), where $$ \psi = \frac{3 - \sqrt{5}}{2} \quad\text{and}\quad \delta = 2\varepsilon \left( 1 + \frac{\log(1/\varepsilon)}{\log |F|} \right). $$
The theorem is now a self-contained object: a reader (or a model) can understand what it asserts without reconstructing the paper’s narrative order. This makes it suitable for semantic search, embedding, and dependency analysis.
Inferring dependencies between artifacts
Even after extracting artifacts and linking explicit \ref{...} citations, the dependency graph is incomplete: mathematicians often rely on earlier lemmas implicitly (“by standard compactness arguments…”, “using the previous construction…”) without naming them.
We can recover many of these missing edges with an LLM, but there’s a combinatorial trap: a paper with (N) artifacts has (O(N^2)) pairs, and asking an LLM to compare every pair is slow and expensive.
This is exactly where artifact enhancement becomes useful: once each artifact is augmented with its key terms and prerequisite definitions, we can cheaply build a conceptual fingerprint of each statement. Candidate dependencies can then be proposed between artifacts that look conceptually related5.
 An example of a paper's dependency graph
An example of a paper's dependency graph
Introducing MathXiv
All of this is implemented in open source. The full pipeline, from LaTeX parsing to artifact enhancement and dependency inference, is available in the arxitex repository.
On top of that, we release:
- a Hugging Face dataset containing 10k fully processed mathematics papers, with extracted and enhanced artifacts, and
- a web application for exploring papers as dependency graphs rather than linear PDFs.
Together, these form MathXiv, a structured, machine-readable layer over the mathematical literature, where theorems and definitions are first-class objects rather than buried paragraphs.
Next time, we will focus on what this representation enables: semantic search over mathematical statements and new ways of navigating mathematics that are impossible with keyword search alone.
-
“Mathematicians just make their results freely available, as if they were on shelves where anyone can fetch them.” ↩
-
But let’s not forget the latest CNRS initiative, Geodesic that just started in September 2025. ↩
-
To highligth this clearly, a quick experiment was ran (Math Artifact Retrieval Scoring) to ask an LLM to suggest an article where to find a randomly drawn result from a random paper… and it never could. ↩
-
This is very similar to techniques such as Anthropic’s Contextual Retrieval. ↩
-
Remember now our first SGA 4½ graph? ↩