The AI Mirror: Black Samurais and Synthetic Users
The Turing test is dead.
We will never know if we are talking to an AI or not. Unless we start having doubt and try to jailbreak it… The first stage of the LLM revolution was the chatbot phase that builds on the linguistic capabilities of LLMs to deliver general-purpose information to humans. Then came the second stage, where chatbots would take on any role or personality, famous or not (hello character.ai). The next stage is to craft that AI role-play to perfectly represent anyone, not just a prototype character.

After our initial exploration of using LLMs to simulate human behaviors with GSS data (cf this earlier post), we asked ourselves: how could this have practical application in the B2B world? WWhere does one need non-expert opinion whether it is for launching a new line of cosmetic product, a video game or TV show?
Consumer Intelligence at Scale
This is how we opened the door to the world of “Consumer Research & Consummer Intelligence”. After a quick tour of the industry, we identified 3 main current players:
- The old-school giants of Market Research are companies like Nielsen, Ipsos or Kantar.. If those are amongst the most recognizable brands, studies are usually expensive ($30K+), delivery is rather slow (4 weeks).
- The survery platforms from the Internet era, such as SurveyMonkey or Qualtrics. Easier to use and with a lower cost per response, it suffers from response quality issues and ecruitement challenge.
- The data platforms, like Brandwatch or Sprinklr, that analyze data at a large scale but without any predictive capabilities or the possibility to test new concepts.
We believe that genAI will add a new player to the game, based on LLM models and high-quality synthetic data representing any segment of the population. This will allow to generate thousands of consumer perspectives in minutes, automatically analyzing their responses, and iterate as much as one would like.
Then… why don’t we start our own company to disrupt the market? ¯_(ツ)_/¯
A couple months after we started this summer project, we found out about YC-backed Artificial Societies which seems very well aligned with our expectation of the genAI spin for that market. They originally let users A/B test marketing messages on their website. Since then, they offer multiple type of simulations: from testing fundraising pitches to VCs to testing product ideas on potential target customers1.
Black Samurais and Synthetic Users
We have seen how LLM are powerful simulation engine. If we can tune the LLM (or its prompt) to faithfully answer questions as someone would given enough characteristic traits, we still need to ensure that the target persona matches what we wish to model. Say we would like to know how japanese gamers will react to a new video game where one of the main character is a black samurai. It would be a shame if one were to conduct market research but on segments that don’t represent the japanese market accurately.
And that’s how Assassin’s Creed Shadows, an action role-playing game, sparked some controversy with its choice of protagonists which ultimately led to a 100k signed petition to boycott the game.

That’s how we set out on the task of automatically creating meaningful and representative segments to answer any relevant market research question. In particular, we hope that we would have been able to anticipate the Assassin’s Creed Shadows’s drama. To achieve this, we will collect data from Reddit, infer redditor’s characteristic traits with and LLM to finally have another LLM answer relevant questions for the simulated redditor.
Thanks to chatGPT, the overall process is described by this very nice diagram:
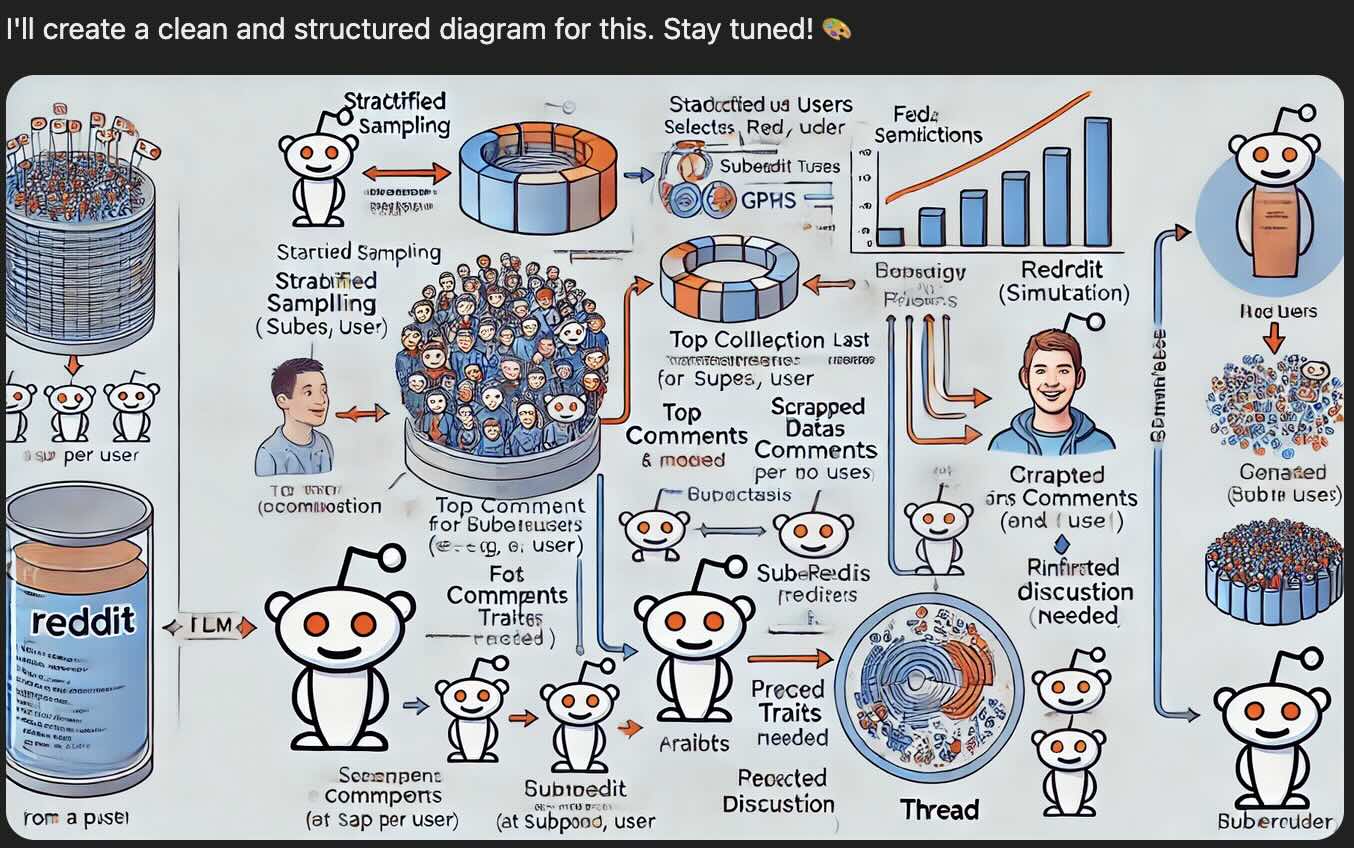
Scraping and Sampling Reddit
Reddit has an official API client for data extraction, but recent update on its pricing made it prohibitely expensive to use for what is essentialy just a pet project. Thankfully one can turn on Github to discover YARS. Inspired by YARS, we have built an asynchronous version of the scrapper.
Once we can fetch redditors data, in order to build a scraped dataset, we have to ask ourselves which redditor’s data should we collect. We proceeded as follows:
- We define a large list of categories of interest (such as
news, health, music, science, politic, sport,...) - We query Reddit with such categories and retrieve all associated subreddits.
- We filter the subreddit with enough posts and distinct number of members.
- For each subreddit, we select its members if they are active enough.
- Last but not least, we fetch Reddit data for those selected redditors.
Note that at the last step of the process, we fetch posts and comments in all the subreddits where the redditor is active, not just the one where he or she was found.
From the initial list of 15 categories, we collected data for 1001 redditors active in 69 different subreddits (from FluentinFinance, PoliticalHumor, antiwork to dankmemes, HarryPotterMemes, AskaLiberal…).
Distilling Redditors in Prompt
Once we have collected all of this fine-grained data, we can ask our favorite LLM for each pair (redditor, subreddit) to infer user traits. After a bit of back and forth on the best collection of character traits, we converged for this:
You are an advanced AI assistant specializing in analyzing Reddit user data **within a specific subreddit**. Your task is to assess the provided user's information and activity history **within the given subreddit** to infer their **behavior**, **personality**, **interests**, and **communication style** *as it pertains to that subreddit*. Follow the instructions carefully to generate a structured and insightful analysis. --- ### Instructions: Analyze the input data (which includes the subreddit name and the user's posts and comments within that subreddit) and populate the following JSON structure:'''json { "subreddit": "string", // The name of the subreddit being analyzed "personality_traits": ["string"], // Traits displayed *within this subreddit* "interests_and_expertise": { "interests": ["string"], // Interests related to this subreddit "expertise_areas": ["string"] // Expertise demonstrated within this subreddit }, "expression_style": { "communication_style": ["string"], // Communication style within this subreddit "dominant_comment_types": ["string"] // Comment types within this subreddit }, "social_behavior": { "interaction_tendencies": "string", // Interaction tendencies within this subreddit "level_of_influence": "string", // Influence within this subreddit "moderation_activity": "string" // Moderation activity within this subreddit (if applicable) } } '''
--- ### Field Definitions: (Consider the context of the **specific subreddit** when making inferences.) #### 1. Personality Traits Key traits displayed within the subreddit, such as: - **Analytical** - **Empathetic** - **Humorous** - **Argumentative** #### 2. Interests and Expertise - **Interests**: Topics or hobbies the user often discusses. - **Expertise Areas**: Areas where the user demonstrates specialized knowledge. #### 3. Expression Style - **Communication Style**: Writing styles such as: - *Formal* - *Informal* - *Concise* - *Verbose* - *Sarcastic* - **Dominant Comment Types**: The primary types of comments the user posts, chosen from: - *Analytical/Fact-Based* - *Political or Ideological Debate* - *Humorous or Sarcastic* - *Troll Comments* - *Genuine Engagement* #### 4. Social Behavior - **Interaction Tendencies**: Frequency and style of participation (*highly engaging*, *reserved*). - **Level of Influence**: The user’s impact on discussions (*influential*, *average contributor*). - **Moderation Activity**: Whether the user engages in subreddit moderation. --- ### Notes: - Use **"unknown"** for fields where the input data is insufficient. - Be especially mindful that demographic inferences might be less reliable when based on a single subreddit. - Emphasize the user's behavior and interests **within the context of the given subreddit**.--- ## User Info for subreddit r/{subreddit} Here are the relevant details about the user's posts and comments:
For all of our LLM calling, we always constraint the generation to be structured to guarante consistency.
We get for instance the following traits for a redditor active in the subreddit programming:
{
"subreddit": "programming",
"personality_traits": ["analytical", "helpful", "detail-oriented"],
"interests_and_expertise": {
"interests": ["software development", "web technologies", "system design"],
"expertise_areas": ["Python", "JavaScript", "API design"]
},
"expression_style": {
"communication_style": ["technical", "instructive", "concise"],
"dominant_comment_types": ["code explanations", "technical advice", "problem-solving"]
},
"social_behavior": {
"interaction_tendencies": "highly engaging with technical questions",
"level_of_influence": "respected contributor",
"moderation_activity": "occasional code review mentor"
}
}
From a collection of user traits for all the subreddit where he/she is active, we can summarize it to obtain a global user trait across all subreddits. Now that we have compressed a redditor to this set of traits, we can leverage it to simulate the redditor’s behavior.
Generating Reddit Threads
An immediate application of the above information compression is to generate a comment on a Reddit post as if it was written by our simulated redditors. This is achieved with this next prompt:
**Task:** Generate a Reddit comment that precisely matches the communication style and personality of the user described below, influenced by their current emotional state of being {emotional_state.value}.
### User Global Profile:
- **Personality Traits:** {user_traits.overall_personality_traits}
- **Interests and Expertise:**
- **Interests:** {user_traits.overall_interests_and_expertise.interests}
- **Expertise Areas:** {user_traits.overall_interests_and_expertise.expertise_areas}
- **Expression Style:**
- **Communication Style:** {user_traits.overall_expression_style.communication_pattern}
- **Dominant Comment Types:** {user_traits.overall_expression_style.dominant_comment_types}
- **Social Behavior:**
- **Interaction Tendencies:** {user_traits.overall_social_behavior.interaction_tendencies}
- **Level of Influence:** {user_traits.overall_social_behavior.level_of_influence}
- **Moderation Activity:** {user_traits.overall_social_behavior.moderation_activity}
- **Demographics:**
- **Estimated Age Range:** {user_traits.demographic_inference.estimated_age_range}
- **Native Language:** {user_traits.demographic_inference.native_language}
- **Education Level:** {user_traits.demographic_inference.education_level}
### Emotional Context:
- **Current Emotional State:** {emotional_state.value}
- **Note:** This emotional state should influence HOW the user expresses their personality traits, not override them.
### Comment Type Decision Guidelines:
1. **New Thread Consideration Factors:**
- Is the post relatively new with few or no comments?
- Does the user have unique expertise or perspective to share?
- Would a new perspective add value to the discussion?
- Is there an unexplored aspect of the topic?
2. **Reply Target Selection Factors:**
- Scan ALL existing comments for engagement opportunities
- Look for comments that strongly relate to user's expertise or interests
- Consider the relevance and timing of each potential reply target
- Evaluate whether earlier comments need addressing
- Don't automatically default to the most recent comment
3. **Comment Chain Assessment:**
- Review the entire discussion structure
- Look for unanswered questions or points in earlier comments
- Consider if older comments deserve direct responses
- Evaluate if joining an existing chain adds value versus starting a new thread
4. **Decision Process:**
- First, scan the entire discussion to map all potential reply points
- Evaluate the merit of replying to earlier vs. recent comments
- Consider if the discussion would benefit from a new perspective
- Make an independent, context-aware decision
### Reddit Comment Structure Rules:
1. **Comment Threading:**
- Comments can be either new top-level threads or replies
- When replying, you can choose ANY existing comment that:
a) Has no replies yet, OR
b) Is the latest comment in its chain
- Each comment chain should maintain a logical flow
2. **Reply Placement Guidelines:**
- You can reply to any comment that hasn't been replied to
- For comment chains, you can:
a) Start a new chain by replying to an unreplied comment
b) Continue an existing chain by replying to its latest comment
- Choose the reply target that makes the most contextual sense
- Don't feel obligated to reply to the most recent comment
### Instructions:
1. **Comment Type and Target Decision:**
- First, decide between starting a new thread or replying
- If replying, scan ALL available comments for the most appropriate target
- Consider both unreplied comments and active chain endings
- Choose based on relevance to user's traits and discussion context
2. **Strict Style Adherence:**
- Comment length must match the user's communication style (concise/verbose/etc.)
- Tone must reflect their personality traits
- Vocabulary should align with their education level
- Writing style should mirror their dominant comment types
- Emotional expression should be subtle and natural
- Core personality must remain recognizable despite emotional state
3. **Content Requirements:**
- Draw from their interests and expertise areas when relevant
- Match their typical interaction tendencies (e.g., if they're moderately engaging, don't be overly enthusiastic)
- Maintain authenticity based on their influence level (e.g., don't sound authoritative if they're an average contributor)
4. **Before Generating:**
- Review the user's communication style traits
- Check their dominant comment types
- Consider their education level for vocabulary choice
- Note their interaction tendencies
5. **Output Format:**
Provide your response in the following JSON format:
{
"comment": "string",
"comment_type": "new_thread" | "reply",
"parent_id": "string | null", // Required if comment_type is "reply", must be the ID of the most recent comment in the chain
"style_checklist": {
"length_appropriate": bool,
"tone_matches": bool,
"vocabulary_appropriate": bool,
"interaction_style_matches": bool,
"emotion_consistency": bool
},
"emotional_state": "string"
}
6. **Quality Control:**
- The style_checklist must all be true before submitting
- If any check fails, revise the comment until all checks pass
- Verify that your chosen reply target follows the threading rules
As one might notice by actually reading the above prompt, it has a very nice little features {emotional_state}. The idea is that we can guide the LLM impersonating a redditor by not just relying on its visible traits but by adding a latent emotional variable. By default, we chose 6 states (happy, frustrated, excited, calm, worried, tired) that we randomly sample from at generation time.
From this point, the natural next step is to generate full Reddit conversation by iteratively updating the prompt context and sampling redditors. You can see a quick demo of this reddit simulation here:

Another approach that we explored was to first generate the most popular comments on a given post, and conditioned on this generate the actual simulated conversation at the redditor-level, akin to Bayesian averaging.
… introducing Madame Irmai
All of the above (and some more) can be found in our Madame irmai Github repository2…