Have your AIs talk to my AIs
In the first wave of generative AI talking over the world, right after the chatGPT moment, came this paper Generative Agents: Interactive Simulacra of Human Behavior.
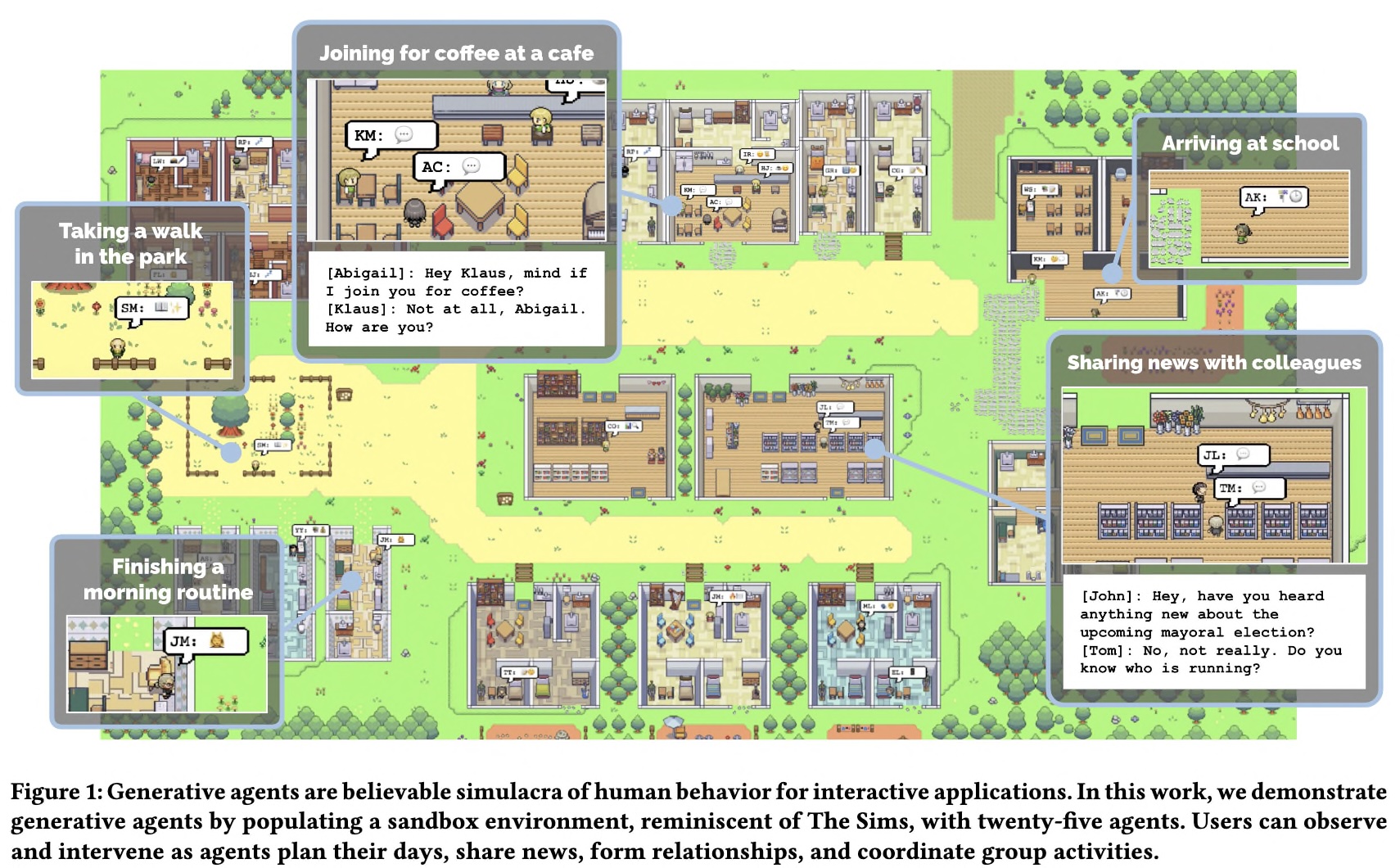
Beyond its undeniable madeleine de Proust effect which puts us back as the children we were, playing Sim’s (and probably experimeting with a form of virtual crualty when removing that ladder from the swimming pool), the paper caught the attention of everyone. I wonder how this could be applied to simulate societies, to understand sociological and economical phenomena. Or perhaps simply to simulate my company’s dynamics 1, and who knows even remove meetings entirely if we can simulate everyone’s interactions.
In a similar vein, many research papers explored that idea, such as Approaching Human-Level Forecasting with Language Models, or Large language models surpass human experts in predicting neuroscience results. Then in November 2024, the Stanford team behing the first article published a follow-up paper Generative Agent Simulations of 1,000 People. They thorougly interviewed over a thousand people and distilled their perceive personality traits to ask an LLM to impersonate them in order to answer survey questions from the General Social Survey (GSS). And of course, they showed they can reproduce very accurately the actual interviewees answers to those questions.
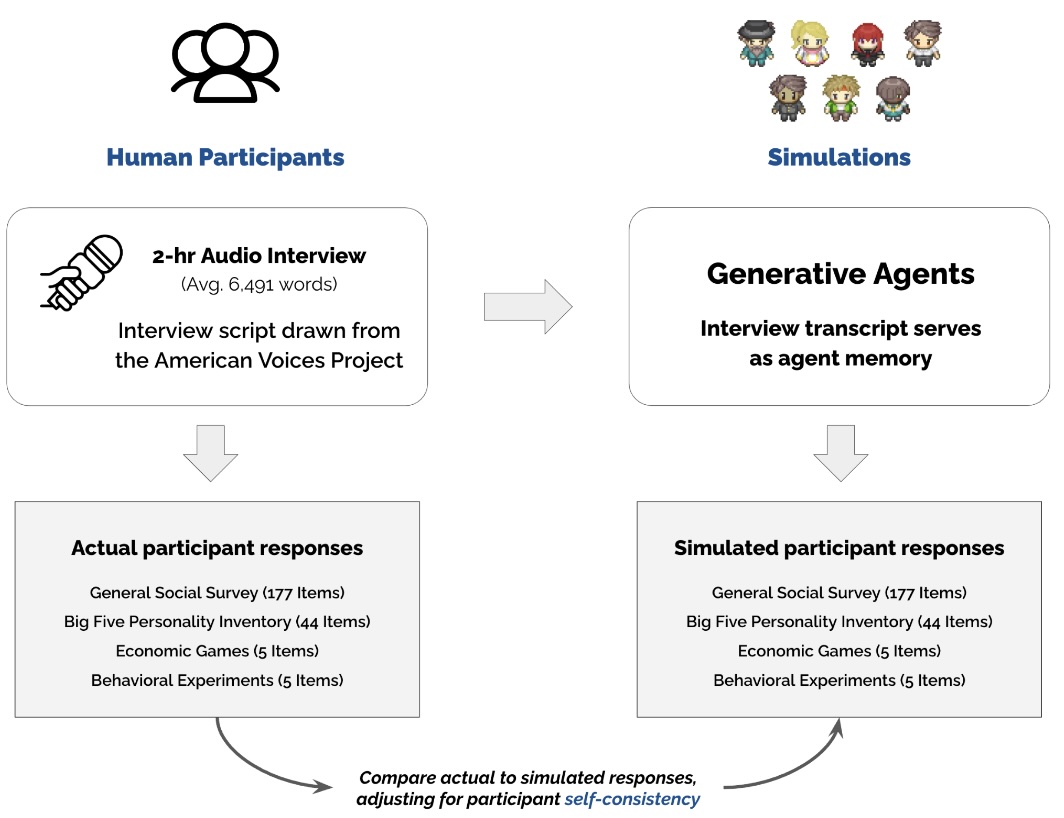
This makes one wonder how can this impact our social interactions, all the cumbersome ones we would rather avoid or the low-values one, such as gathering non-expert opinions on non-expert matters. Do you prefer the blue or the red logo? Would you play a black samurai in a video game? In business, it even has a name, it’s called the “Voice of the customer”.
The GSS Dream, the Data Nightmare
Inspired by this line of research, I set out to reproduce their GSS experiment slightly differently. Indeed GSS doesn’t simply provide their questionnaires but also data on their panel at the finest level, that is each respondent’s answer to each question. The GSS proposes the longest-running american longitudinal survey, originally created in 1972 by the National Opinion Research Center at the University of Chicago. The 2022 edition of the cross-sectional survey had over 4000 respondents and over 1000 questions.
Digging in the questionnaire, we found some interesting one such as Should government aid blacks? (see helpblk) or the feeling thermometer:jews which asks the respondent to rate this group using a thermometer.

Unfortunately getting and processing the data was a bit challenging, as GSS offers data only in formats that nightmares are made of: SPSS, Stata and SAS. But what’s to fear when you have AI at your fingertips and can convert any data from one format to another. Once you get the data in a readable format (a csv or jsonl file), you are not quite done as everything as been category-coded, and the catogies mapping are detailed in little (a mere 700 page) code books such as this one. To add insult to the injury there is GSS data explorer where you can query variable one by one 2. Thankfully, out of nowhere on github, appeared gssrdoc documentation in structured files. Althought this was in R, it was only a matter of chatGPT providing adequate script to convert it to nice little csv files (which are now available here).
Survey Simulations with LLM
After this incredible data journey, we can finally get to work and ask our favorite LLM to answer survey questions assuming a respondant description. We select 28 informational features to serve as the respondent description such as age, race, education, health, political views,.... We then select 25 questions to ask those respondents such as kidsocst(does having children increases social standing in society?) or fair (Do you think most people would try to take advantage of you if they got a chance, or would they try to be fair?).
This is an example of the prompt for a given respondent.
We know the following information about the respondent:
They are 89 or older years old. They are female. They are of white racial background. They identify as italy ethnic background. Their highest degree is high school. They currently live in the new england region. Their current marital status is: never married. Their work status is currently: retired. Their income is $25,000 or more. They practice catholic religion. Politically, they consider themselves conservative. They describe their overall happiness as pretty happy. They report their health as poor. When they were 16, they lived in in a medium-size city (50,000-250,000). Since the age of 16, they have lived in same state, same city. Their sexual orientation is: heterosexual or straight. Their occupation category is civic, social, advocacy organizations, and grantmaking and giving services. Politically, they consider themselves a not very strong democrat.
Together with an example question such as:
Answer the following question about this person: 'How often do the demands of your family interfere with your work on the job?'
The allowed values are: ['.i: Inapplicable', '.n: No answer', '.d: Do not Know/Cannot Choose', 'Often', 'Sometimes', 'Rarely', 'Never']
As a first experiment, we randomly selected 20 respondents and 20 questions. This is of course very partial and limited information but enough for our LLM budget to start with. We check whether we get the exact same response from the LLM as the respondent’s original response. This results in 43% accuracy which given the nature of multiple answer questions is more than decent score (if all questions had 3 possibles answers, a random model will get an accuracy of (1/3)^400).
This is only a starting point, no effort has been made to craft the prompt into a more structured one or a few-shot approach 3, so there is very little doubt we could get that accuracy very high.
Another direct extension would be to apply this longitudinal studies and to learn a prompt (or a model) on the first wave, and validate on the next ones.
SurvAI
All the code used to preprocess GSS data and to make LLM inference will be available shortly 🤞…