The pullback, agentic search engine for mathematical statements
As explored previously, a working scientist uses a search engine for vastly different tasks, ranging from literature surveys (“what is categorification?”) to concept analogies (“is drift detection in machine learning the same as propensity positivity detection?”).
Yet one category of search remains largely unsupported: statement-level retrieval. By statement-level retrieval, we mean searching directly for mathematical or scientific artifacts (definitions, theorems, equations, reactions, or constructions) rather than for papers themselves.
This gap persists whether you are a mathematician hunting for a specific PDE or a chemist searching for a distinct molecular reaction. Addressing this gap was the goal of the arxitex project. Focusing on mathematics, it began as a LaTeX parser designed to extract artifacts and infer dependencies between them, a necessary first step before indexing. But extraction was never the end goal, the real objective was retrieval.
The Pullback: an agentic math statement search engine
… and this is exactly what we set to achieve with the pullback!
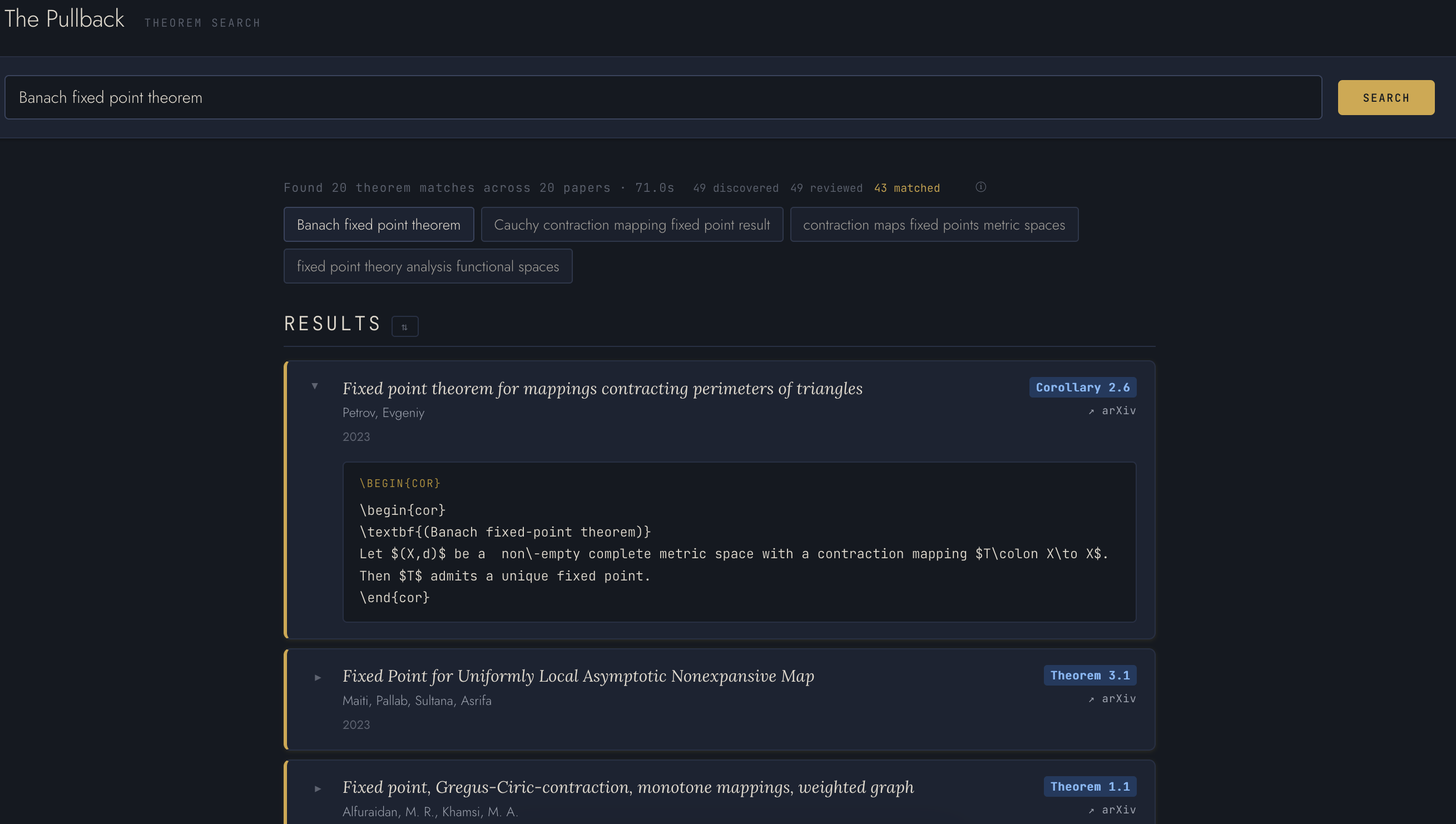 the pullback
the pullback
But before diving into how this was built, let’s take a step back to unpack what’s actually happening under the hood.
The agentic shortcut
Here is the standard recipe to build a search engine. First, collect the data. Next, carefully curate it. Settle on an indexing strategy and fine-tune your retrieval methods. And voilà. As an optional extension, consider user interaction, which is the subtle boundary that separates a research prototype from an actual product.
By late 2025, coding agents had become powerful enough to make rapid experimentation with unconventional architectures economically viable.
The classical approach to building a search engine comes at a steep infrastructural price. You need dedicated storage for raw and indexed data, alongside the compute infrastructure to process incoming user queries and calculate vector matches.
Or, you can do everything on the fly and don’t build and index at all.
Pullback treats existing academic search engines as a distributed retrieval layer. Rather than maintaining its own artifact index, it discovers candidate papers through iterative query reformulation, extracts mathematical artifacts on demand, and ranks them against the user’s original query1. Of course, this introduces a clear architectural tradeoff. What is gained in simplicity is potentially lost in precision: public search engines—whether generic like Tavily and Serp, or academic like Semantic Scholar, OpenAlex, and arXiv primarily index paper metadata rather than the in-line mathematical content1.
To make this architecture truly agentic, an LLM orchestrator is placed on top. A fitting title for this role is The Librarian: an agent tasked with evaluating whether the returned results truly satisfy the user’s intent. If they fall short, the Librarian guides the next iteration of query reformulation and discovery. And when the system still fails to meet expectations, it opens a dedicated loop for the user to provide direct feedback, steering the next round of reasoning.
If this tool was meant for personal use only, it could have remained a loose collection of skills and local tools wrapped into agents. But we live in a strange, intermediate era. While some feel the only interface left worth using is a terminal, most users still enjoy a proper UI. Because this tool is intended to be used by others, it felt like the perfect excuse to take pydanticAI for a spin (or, more accurately, to ask my AI assistants to do so).
Matlas & TheoremSearch: The Confirmation Signal
In the six months it took to release this proof-of-concept, two independent initiatives emerged that followed the traditional well- structured path. They both collected, curated, and indexed data at the artifact level, implemented a retrieval method, and deployed a live system.
The first to arrive was TheoremSearch from the University of Washington. Much like Arxitex, their pipeline adds a natural language explanation to each extracted mathematical statement, which they refer to as a “slogan.” This slogan is what ultimately gets indexed and searched against. Their ingestion pipeline successfully collected over 9 million statements spanning arXiv, the Stacks Project, and more.
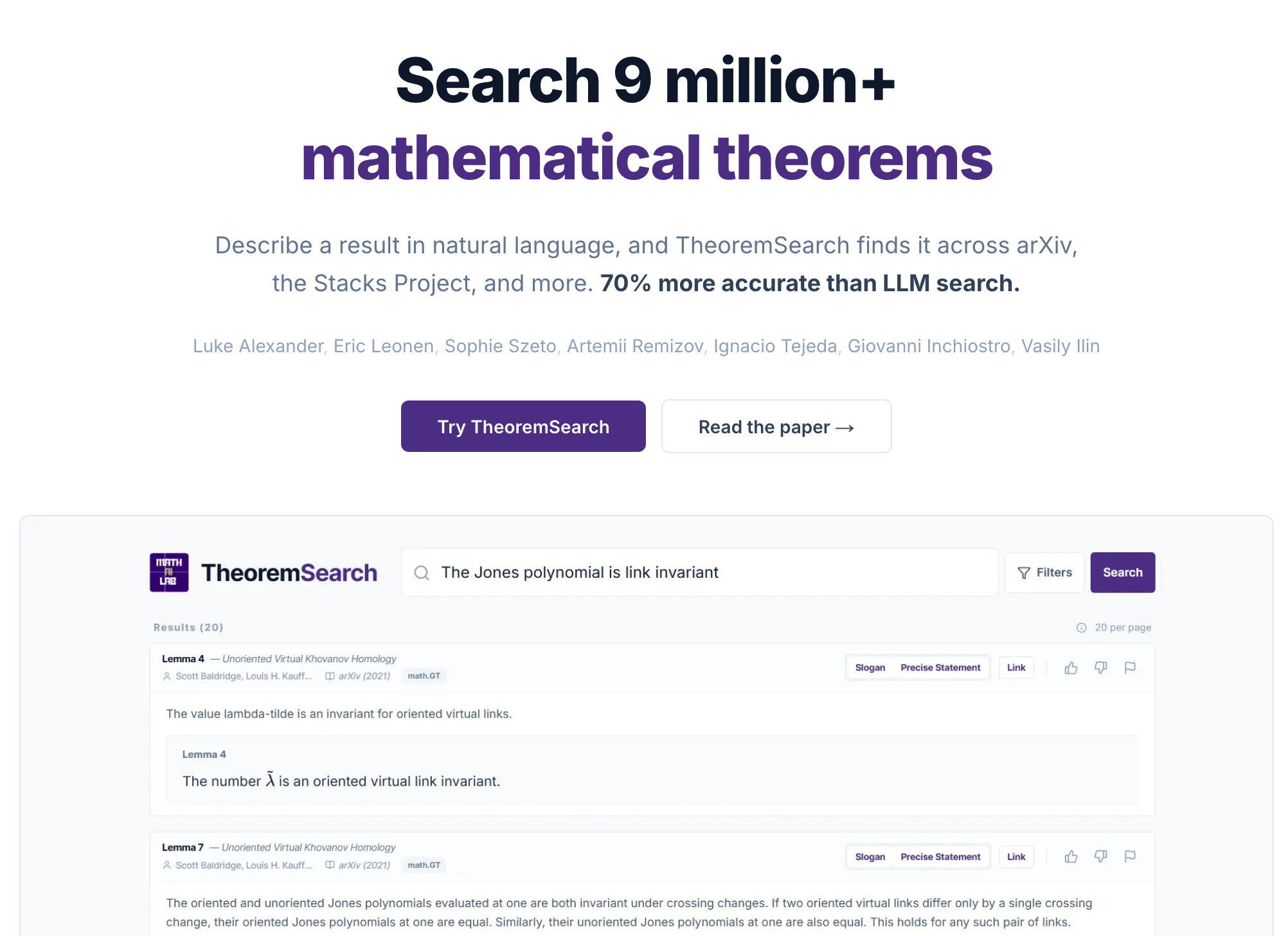
They also published an evaluation dataset consisting of 110 queries proposed by working mathematicians to benchmark system performance—a test set that was promptly borrowed to evaluate the pullback.
The second parallel initiative is Matlas from Peking University (which truly is a fantastic name1). The high-level pipeline mirrors TheoremSearch closely, with one critical distinction: the underlying training data. The creators of Matlas chose not to limit themselves strictly to open-access or license-friendly literature… but ultimately assembles about the same number of statements (slightly over 8 millions).

Is Statement-Level Retrieval “Solved”?
While both prototypes are moving in the right direction, they remain far from satisfying the long-term research needs of working mathematicians. This friction may stem from a simple reality: these systems are rarely designed around how mathematicians actually search.
Part of today’s limitations can likely be improved through better retrieval techniques: hybrid lexical-vector systems, late-interaction models such as ColBERT and its successors, or by learning directly from real-time user behavior, a core architectural challenge remains.
Several retrieval failures remain common:
- formula-heavy queries are still difficult,
- composite mathematical objects are often fragmented during retrieval,
- foundational references are rarely surfaced reliably.
Mathematicians rarely search for isolated statements. A useful retrieval system could therefore expose the dependency structure surrounding an object, allowing researchers to move naturally between prerequisites, consequences, and related developments.
Last but not least, true mathematical search therefore requires structural extraction capable of separating assumptions from conclusions and reasoning over the relationships between them. Until retrieval systems can operate at that level of abstraction, statement-level retrieval remains an open problem rather than a solved one.