No Free Lunch For LLMs
In the old world (of traditional ML), to train models, you first needed to collect data, check its quality, and probably label it. All of those steps can be quite costly but you have to pay upfront to claim access to the realm of Machine Learning. Not only is labeled data necessary to train models, it is mandatory to get performance estimation.
Generalization bounds in Statistical Learning theory provide us with guarantees on our models behaviour. Should the data conditions remain the same, metrics are telling us how our models will always perform.
Illustration. Data then Model (pay upfront) vs Model then Data.
With LLM (or for that matter zero/few-shot learning), you have the wahoo demo effect of getting answers immediately. Not only we are biased by our imagination to provide test examples but to safely deply such system, we need guarantees on its external validity.
And as in the old world, to achieve validation, we need labeled data representative of our expected usage scenario. Lowering the entry barrier to AI means people with no training in data science or machine learning will ultimately fell into the trough of disillusionment if we don’t tell them about the road that separates a flashy demo from a production-ready feature.
Bootstrapping Task Validation
The (almost) meta spin here is that you can use LLM to synthetically generate or at least augment your validation data. For instance, suppose you are doing code generation from natural text.
Starting from our original pair of (query, code), you can generate a set of multiple {(query_1, code), (query_2, code), … } by asking for semantic reformulation of the query. You can also guide the reformulation to account for some implicit factors, such as tone or level of expertise. Things like “Reformulate the original query as if you were {a 60 years old novice/an expert/ drunk}”. This naturally adds diversity to the input feature space.
As very often in a constant evolving field, I later discovered that generating task instructions together with input-output pairs is the basis of the instruction tuning procedure presented in Self-Instruct: Aligning Language Models with Self-Generated Instructions (github).
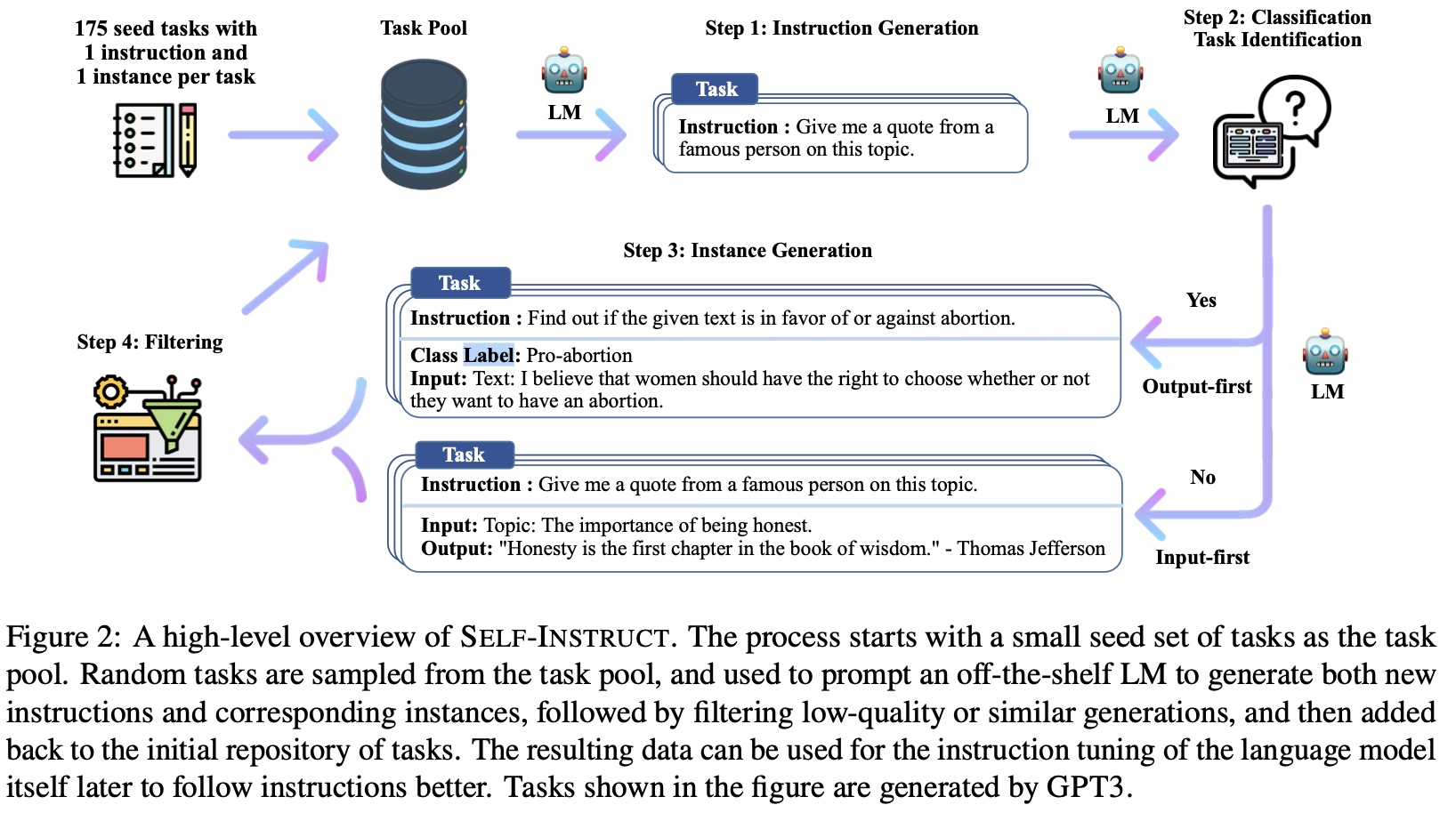
If Self-Instruct aims at improving the performance of instruction-tuning LLMs, we can simply use it to bootstrap our validation dataset.
LLM-based Synthetic Data Generation
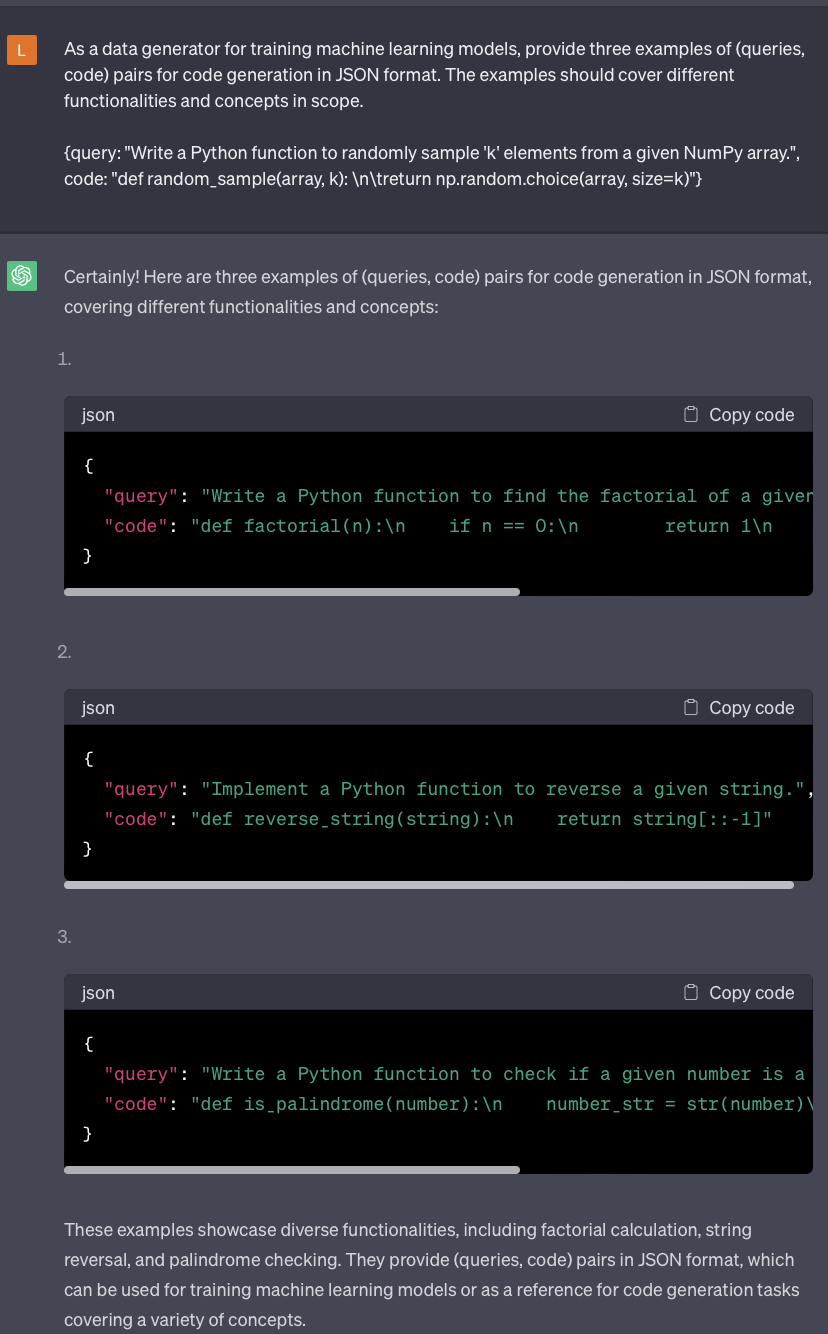
Indeed, we can prompt LLM, in a meta-learning fashion, to provide diverse samples representative of our task of interest.
A starter ChatGPT prompt to iterate on could look like:
Specific to tabular data, LLM are realistic tabular generation proposed a synthetic data generation method starting from an initial dataset. After conversion of the dataset into text, the LLM is fine-tuned so that it is then possibe to generate new sample by only providing feature names (which is called “Feature Name Preconditioning”) or a subset of feature values.
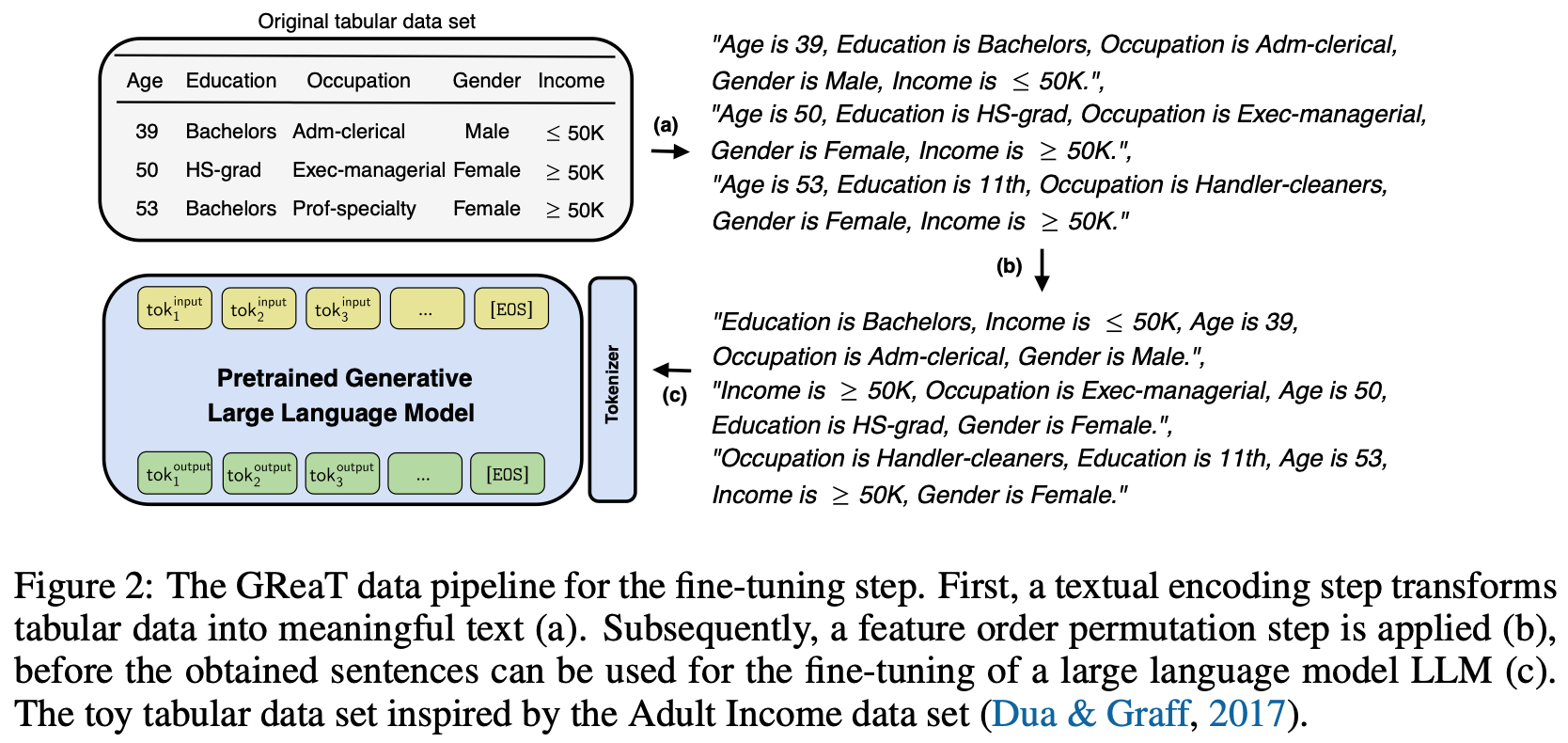
This assumes the existence of an initial dataset large enough for the model to be fine-tuned but we could imagine a similar few-shot learning strategy with very limited number of examples.
Perhaps one last thing that could be interesting to explore is to leverage our favorite LLM to do adversarial augmentation.
No LLM? No problem
Of course, there are already augmentation NLP techniques1 which are not relying on LLMs, such as the ones presented in Beyond Accuracy: Behavioral Testing of NLP Models with CheckList which proposed three types of templated tests of perturbations with expected effects on the model predictions. For instance the transformation describe above falls under their Invariance test.
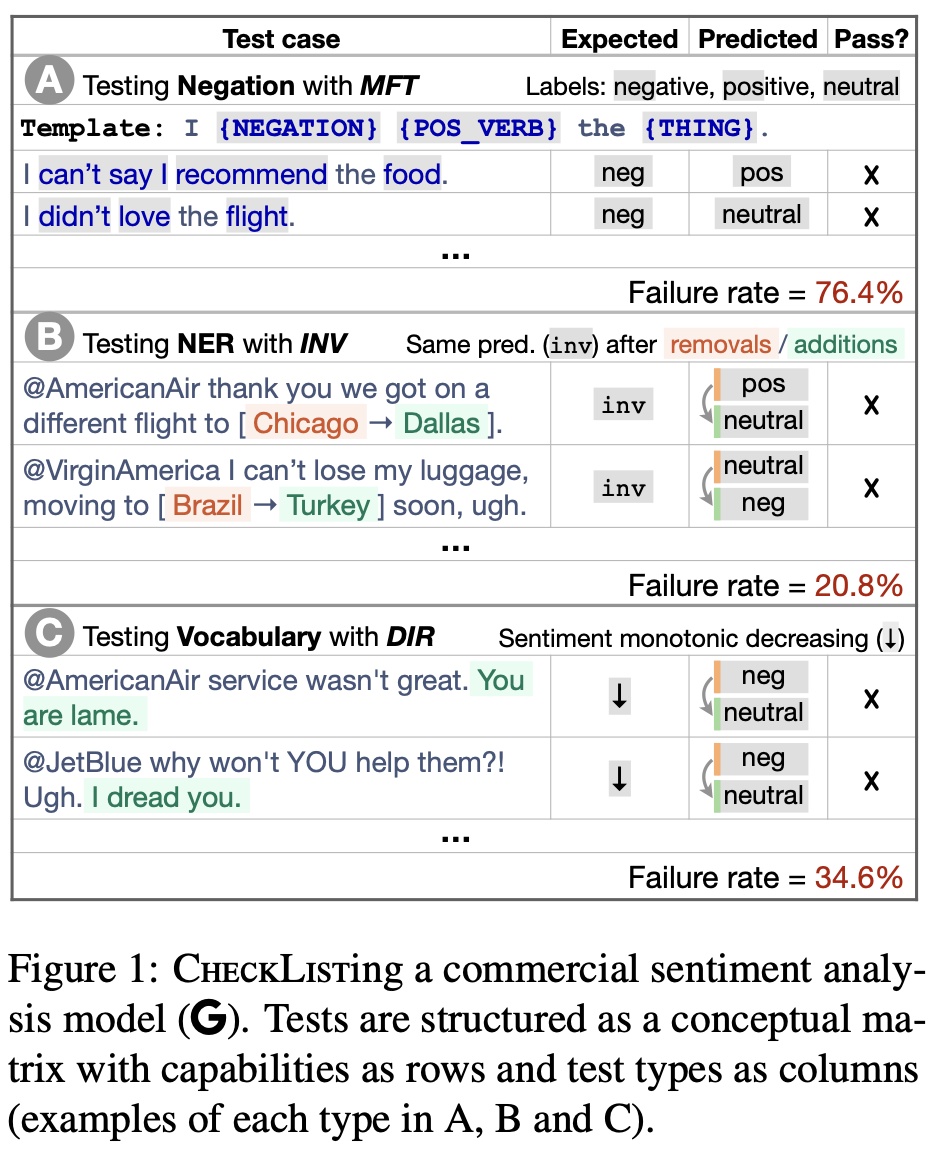
If those templates can be manually filled, the authors also suggest using masked language models to fill-in the masked elements that a user would then validate. For instance “Write MASK code to sort a list” could yield things like (Python, Go, SAS, C,…)”.
This is probably more than enough for most of the tasks but as we saw, with the newly found power of LLMs, we can directly prompt the model with our task instructions.
Any Human Left Standing ?
Because we should never blindly trust any model, LLM or not, specially for validation task, it’s a good idea to make the above strategies human-in-the-loop. That’s why enterprise solutions like scale.ai or snorkel.ai should naturally reap the benefits of this new paradigm. You let the LLMs do as much heavy lifting as possible but keep it on leash with some human monitoring.
As discussed, we always have to pay the price for validation but we get a massive discount with LLMs!